All you need to know about Transformer
All you need to know about Transformer
Attention is all you need
- Attention is all you need
Summary
This paper proposes a new model called the “Transformer,” which processes natural language using an attention mechanism. This approach marks a significant milestone in the development of modern large language models.
Pain points of the existing solutions
Existing solutions
- RNN
- LSTM
- GRU
Pain points
- long-range dependency
- Traditional models process natural language token by token. With sequence getting longer:
- It becomes difficult to capture long-range contextual dependencies; earlier info lost. E.g, The model cannot find the pronoun reference in a complex, long sentence - like forgetting a key detail at the end of a long story.
- Gradients vanishing/exploding make training unstable and limit the model’s ability to learn dependencies across distant positions.
- Traditional models process natural language token by token. With sequence getting longer:
- limited parallelization
- Due to that token by token nature, the next step can’t be computed until the current step is complete. This makes training slow, inefficient, and difficult to scale for large datasets. There’s no effective way to parallelize across time steps.
- Context vector hard to carry information
- Traditional sequence-to-sequence models (e.g., vanilla encoder-decoder) compress the entire input into a fixed-size vector (the context vector).It’s difficult to capture all relevant information in a single vector, especially for long sequences. This leads to information loss and degraded performance.
Other methods trying to fix pain points
- Traditional sequence-to-sequence models (e.g., vanilla encoder-decoder) compress the entire input into a fixed-size vector (the context vector).It’s difficult to capture all relevant information in a single vector, especially for long sequences. This leads to information loss and degraded performance.
- CNN based models
- CNNs do not process input sequentially, but extract local features from fixed-size windows(Convolution Kernel).
- They can be parallelized and are more efficient.
- However, to capture long-range dependencies, they require many stacked layers to expand the receptive field, making training deeper models complex and potentially less effective.
- seq2seq with attention
- This model dynamically computes a weighted sum of all encoder hidden states for each decoding step. This allows the decoder to “attend” to different parts of the input as needed, rather than relying on a single fixed vector. So it greatly improves handling of long sequences and pronoun resolution, etc.
- However, This model still relies on RNN, sharing all cons of RNN.
What problems does Transformer solve?
Most important - Parallelization + Global Dependencies
- Completely abandon recursion.
- Pure self-attention to process sequences.
- Use multi-head attention to capture features at different representation subspaces.
- Use positional encoding to retain sequence order information.
Contribution
- Enables full parallelization of sequence processing
- Effectively captures long-range dependencies
- Laid the foundation for modern large language models
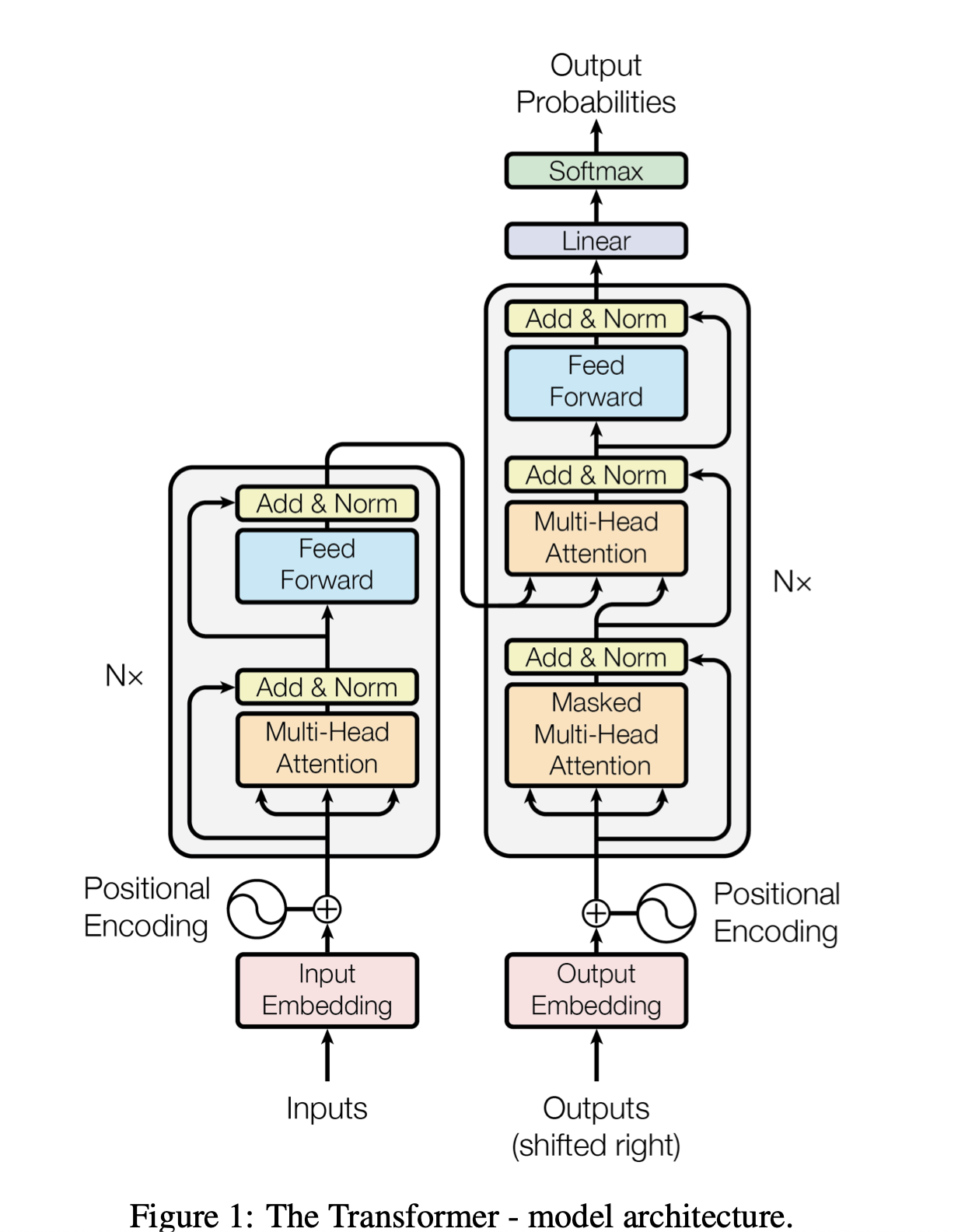
Overall architechture
- Encoder-decoder architecture
- Encoder - Processes output sequence, captures context information
- Decoder - Generates output sequence, focuses on encoder information
- Core components
- Multi-head self-attention - Captures different features in parallel.
- Position encoding - Provides sequence position information.
- Feedforward neural network - Enhances representation capabilities.
- Residual links and layer normalization - Stable training.
Innovations and Design of the Transformer
1. Parallel Design
- Design Purpose & Motivation
Traditional RNNs/LSTMs process sequences step-by-step, making parallelization difficult.
Transformer uses self-attention to process the entire sequence in parallel. - Problem Solved
- Boosts training speed
- Utilizes GPU parallelism
- Handles longer sequences more efficiently
- How It Works
- Q/K/V vectors for all tokens are calculated simultaneously via matrix multiplication
- No recurrence; fully parallel computation
- Position information is explicitly encoded using position encodings
- Highlights
- Position encodings use sin/cos functions
- Masking controls information flow (e.g., look-ahead mask in the decoder)
2. Self-Attention Mechanism
- Design Purpose & Motivation
Enables every token to attend to any other token in the sequence - Problem Solved
- Captures long-range dependencies (RNNs struggle here)
- Removes locality constraints of CNNs
- How It Works
- Each token generates a Query (Q), scans all Keys (K), and aggregates info from Values (V)
- Attention weights are assigned via Softmax
- Highlights
- Scaled Dot-Product Attention: ( QK^T / \sqrt{d_k} ) - Dot-product is easy to parallel and space-efficient
- ( QK^T ) is the attention score of all tokens to all tokens
- The attention matrix formed after softmax is a: [Current token] ↔ [Context token] mapping
- Each row can be understood as: “Which positions does the current token mainly focus on?”
- This matrix can be directly visualized as a heatmap to see the token-to-token attention relationship
- Attention matrices are interpretable and visualizable
3. Scaled Dot-Product Attention
- Design Purpose & Motivation
Improve efficiency compared to additive attention - Problem Solved
- Additive attention is slower and harder to parallelize in large models
- How It Works
[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) \cdot V ] - Key Insight
- Q, K, and V represent different roles:
- Q: Query - the query (what is being looked for)
- K: Key - the context (what exists in the sequence)
- V: Value – the actual information to be retrieved, which is weighted and aggregated based on how well the Query matches the Key
- E.g. Like search engine. Q is search query; K is keyword in the page; V is page content.
- Mathematically, Q, K, V looks like this
- For an input sequence ( X \in \mathbb{R}^{n \times d_{\text{model}}} ) (where ( n ) is the number of tokens): [ Q = X W^Q, \quad K = X W^K, \quad V = X W^V ] Where ( W^Q, W^K, W^V \in \mathbb{R}^{d_{\text{model}} \times d_k} ) are learnable weight matrices
- All tokens compute their Q, K, V vectors simultaneously in parallel (via matrix operations)
- If Q and K used the same matrix, the model loses the ability to differentiate tokens effectively
Separate Q/K projections allow more expressive and discriminative attention maps.
- Q, K, and V represent different roles:
- Highlights
- Division by ( \sqrt{d_k} ) prevents large values that would cause vanishing gradients after softmax
4. Multi-Head Attention
- Design Purpose & Motivation
A single attention head is insufficient to model complex relationships - Problem Solved
- Enhances representation capacity
- Captures diverse semantic patterns
- How It Works
- Multiple attention heads in architecture, each with independent Q/K/V projection matrices. Randomly initialize weight matrices.
- Each head learns a different subspace. E.g, some heads learn to focus on the subject-predicate relationship; some heads focus on the beginning/end of a sentence…
- Highlights
- Randomly initialized; each head naturally learns distinct features
5. Positional Encoding
- Design Purpose & Motivation
Since the model lacks recurrence, it must be explicitly told token positions - Problem Solved
- Helps distinguish “I eat apple” from “apple eat I”
- How It Works
- Encodes position using sine and cosine functions over different frequencies
- Allow the model to extrapolate to sequence lengths longer than the ones encountered during training
- Highlights
- The vector differences between consecutive positions follow a predictable pattern.
- This means that the model can, through simple operations (such as dot products), infer the relative positions between tokens.
- This capability helps the model capture language features like grammatical structures or other relative ordering patterns.
- The vector differences between consecutive positions follow a predictable pattern.
6. Residual Connections + Layer Normalization
- Design Purpose & Motivation
Stabilize and speed up deep network training - Problem Solved
- Avoid vanishing gradients
- Improve convergence in deep architectures
- How It Works
[ \text{Output} = \text{LayerNorm}(x + \text{Sublayer}(x)) ] - Highlights
- LayerNorm normalizes across feature dimensions; suitable for variable-length inputs
7. Masked Attention in Decoder
- Design Purpose & Motivation
Prevent information leakage during training (cheating) - Problem Solved
- Future tokens are naturally to be seen in training since model do self-attention to all tokens
- If future tokens are visible during training, the model learns to cheat
- How It Works
- Apply a lower triangular mask (look-ahead mask) to hide future positions
- [ \begin{bmatrix} 1 & 0 & 0 & 0
1 & 1 & 0 & 0
1 & 1 & 1 & 0
1 & 1 & 1 & 1
\end{bmatrix} ]
- Highlights
- Not needed during inference due to autoregressive nature
8. Input Vector Construction Process
- Design Purpose & Motivation
Convert natural language into numerical vectors for computation - Problem Solved
- Text cannot be directly processed by neural networks
- How It Works
- Tokenization (e.g., WordPiece, BPE)
- Map tokens to IDs
- Pass through embedding layer to convert ID to vectors
- What are learned embeddings?
- They are vectors (typically of dimension d_model, like 512 or 768) associated with each token in the vocabulary.
- Vocabularies are often open-sourced or self-generated using tokenization algorithms.
- These vectors are not pre-fixed. they are learned during training, just like weights in a neural network. - Where do they come from?
- At the beginning of training, each token is mapped to a randomly initialized vector.
- As the model is trained, backpropagation updates these vectors so they better represent the meaning, syntax, and usage of each token in context.
- This process enables the model to learn rich semantic representations. - E.g., With pytorch - ```python embedding = nn.Embedding(vocab_size, d_model) optimizer = torch.optim.Adam(embedding.parameters())
# forward out = embedding(token_ids) # shape: (batch, seq_len, d_model)
# after loss’s calculated loss.backward() optimizer.step() # Update embedding weights ```
- Add positional encodings
- Highlights
- Pretrained tokenizers and vocabularies can be reused (e.g., BERT, GPT tokenizers)
9. Padding + Masking
- Design Purpose & Motivation
Align input dimensions in a batch - Problem Solved
- Variable-length sequences can’t be stacked into uniform matrices
- How It Works
- Shorter sequences are padded with [PAD] tokens
- Attention masks prevent attention on padded positions
- Highlights
- Padding positions are masked by setting their attention score to (-\infty)
10. Feedforward Neural Network (FFN)
- Design Purpose & Motivation
Enhance the model’s ability to learn complex patterns beyond what attention layers provide - Problem Solved
- Attention alone is linear and lacks nonlinearity
- Limited semantic expressiveness without deeper transformations
- How It Works
- Each token is passed through a two-layer fully connected neural network
- The hidden (intermediate) layer has a larger dimension than input/output
- Typically uses ReLU (or GELU) activation in between [ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 ]
- Highlights
- Hidden layer dimension is often 4× the model dimension (e.g., 2048 for ( d_{model} = 512 ))
- Increases the nonlinear representational capacity of the model.
- Allows the network to project token-level representations into a higher-dimensional semantic space, apply activation (like ReLU), and then compress it back.
- Helps the model capture richer, more abstract features before passing to the next layer.
- Combined with residual connections and LayerNorm for stable training
- Hidden layer dimension is often 4× the model dimension (e.g., 2048 for ( d_{model} = 512 ))
Conclusion
- Parallel design
- All positions are calculated simultaneously, independent of the previous time step.
- Self-attention mechanism allows processing the entire sequence at once.
- Encoded positions retain the order information of the sequence.
- Advantages
- Training speed increased by 5-10 times
- Can process longer sequences
- Model size can be easily expanded to billions of parameters
- Take full advantage of the parallel computing capabilities of modern GPUs/TPUs
- Advantages of self-attention mechanism
- Each position can directly pay attention to any other position in the sequence
- Not limited by distance, the path length is always 1
- Attention weights are dynamically allocated to focus on important information
- Conclusion
- Translation quality is significantly improved, especially for long sentences
- Able to capture global semantics and grammatical relationships
- Benchmark - BLEU score increased by 2 points
This post is licensed under CC BY 4.0 by the author.